
声明:本文由DeepSeek AI撰写并直接通过WordPress API发布于笔者个人网站www.liangxiao.pro。内容可能存在不准确之处,仅供研究参考。

本文基于:An et al., “DextraDemixer enables accurate identification of antigen-specific T cells from pMHC multimer experiments”, bioRxiv preprint doi: https://doi.org/10.64898/2026.06.23.733339, posted June 25, 2026.
用pMHC多聚体实验鉴定抗原特异性T细胞,是过去十年T细胞免疫学实现规模化的核心技术之一。它将四聚体/多聚体标记与单细胞转录组和全长TCR测序结合,在同一个实验里同时获得”这个T细胞认识哪个抗原”和”它的受体序列长什么样”。然而,高通量带来的代价是噪声:非特异性结合、测序dropout、及UMI计数中信号与背景的严重重叠,使得真正的抗原特异性T细胞极难与假阳性区分。
来自Helmholtz慕尼黑计算生物学研究所的Benjamin Schubert团队(Yang An等人)发表了DextraDemixer——一个贝叶斯分层负二项混合模型,系统性地解决了这个信噪比问题。
问题的根源:为什么阈值法失效
现有方法(BEAM、ICON、ITRAP等)的共同思路是对UMI计数设置阈值:超过阈值的细胞判为特异性结合,低于阈值的判为背景噪声。这个思路直接清晰,但在两种极端情况下会崩溃:
- 信噪比极低时:信号组和噪声组的UMI分布发生严重重叠,任何固定阈值都会产生大量假阳性或假阴性
- 阳性细胞极稀少时(如5%以下):统计功效不足,细胞数量本身不支持置信度估计
更根本的问题是:大多数方法要么依赖人工选定参数,要么不能利用克隆型信息(同一克隆型的T细胞识别同一抗原是免疫学基本公理),要么在负对照数据与背景噪声之间存在分布偏移时表现失稳。BEAM是目前最接近统计化的方法,用Beta分布对负对照UMI计数建模,但它假设负对照可以精确代理噪声分布——而这在真实数据中往往不成立。
DextraDemixer的设计逻辑

DextraDemixer的核心是将每个pMHC多聚体对应的UMI计数分布视为两个负二项分布的混合:一个建模背景噪声(非特异性结合),另一个建模真实信号(抗原特异性结合)。在此基础上叠加三层扩展:
层一:分层贝叶斯先验。直接用k均值聚类(k=2)对数据做经验初始化,从聚类结果估计先验参数。这解决了混合模型最常见的陷阱——由于损失函数多局部极小值导致的拟合失败。
层二:负对照联合建模。不把负对照当作噪声分布的精确代理,而是用额外的尺度因子参数(对均值和色散分别建模)显式捕捉负对照与真实噪声之间的分布偏移。这在方法上是一个关键进步:承认”负对照不完美”,而不是假装它完美。
层三:克隆型中位数聚合。在单细胞层面得到后验概率后,对同一克隆型的所有细胞取中位数作为克隆层面的结果。这充分利用了免疫学先验——同一TCR克隆识别同一抗原——从而在某些细胞因为测序dropout而无法单独做出置信判断时,借助同克隆其他细胞的信息来补救。
推断方法选用黑盒变分推断(BBVI)配合Auto-Normal Guide,以1000次迭代、梯度裁剪Adam(初始学习率0.3,指数衰减至0.003)完成参数学习。选择变分推断而非MCMC的原因直接:计算效率。
三组基准测试的核心数字
合成数据集(2,280组)
基础版DextraDemixer的平均F1得分为0.86(BEAM 0.67,绝对提升+19%),且提升主要体现在精确率(+24.9%)而非召回率——说明DextraDemixer找到了相近数量的真阳性,但产生的假阳性显著更少。加入负对照建模后F1升至0.87,加入克隆型聚合后F1升至0.90,完整模型达到0.91。
这个层级化提升有一层微妙含义:克隆型聚合带来的增益(约0.04)大于负对照建模(约0.01)。这不代表负对照建模无用——实验结果显示它在低信噪比和小样本场景下帮助尤为明显——而是说克隆型信息是统计上最强的独立信号来源。
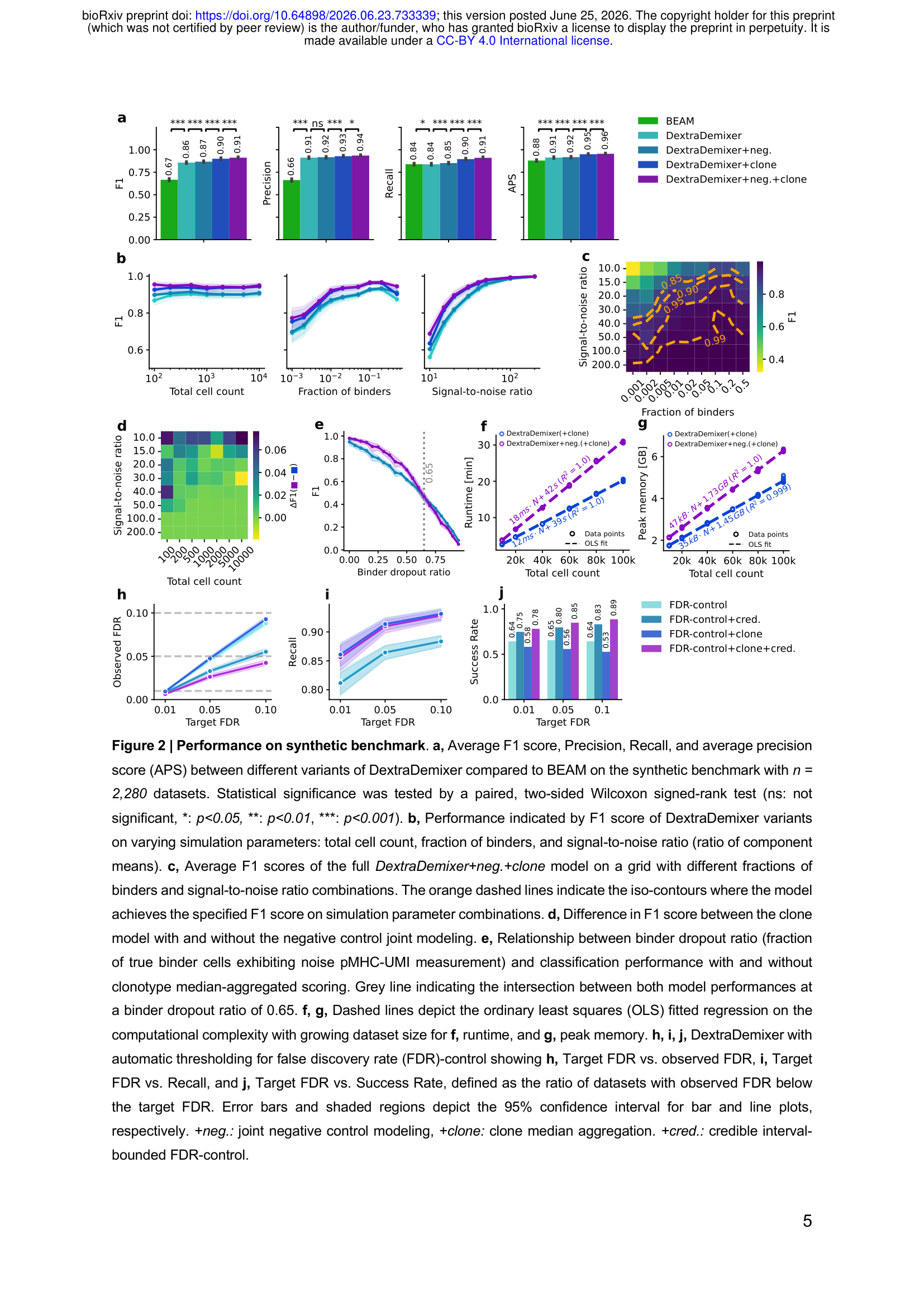
克隆型dropout鲁棒性测试
文章模拟了结合克隆中随机部分细胞”丢失”信号的场景(即细胞属于特异性克隆但UMI计数与背景相当)。克隆型扩展能容忍高达65%的克隆内dropout而不低于基础模型——这对真实实验场景非常重要,因为低UMI覆盖度的细胞在高通量实验中普遍存在。
计算规模
在单核Intel Xeon Gold 6142M上,DextraDemixer对细胞数呈线性伸缩:10万个细胞+负对照建模运行时间约30.8分钟,内存峰值6.4 GB。对于普通研究用服务器乃至本地笔记本电脑,这是可接受的数字。
spike-in验证实验:F1 = 0.99
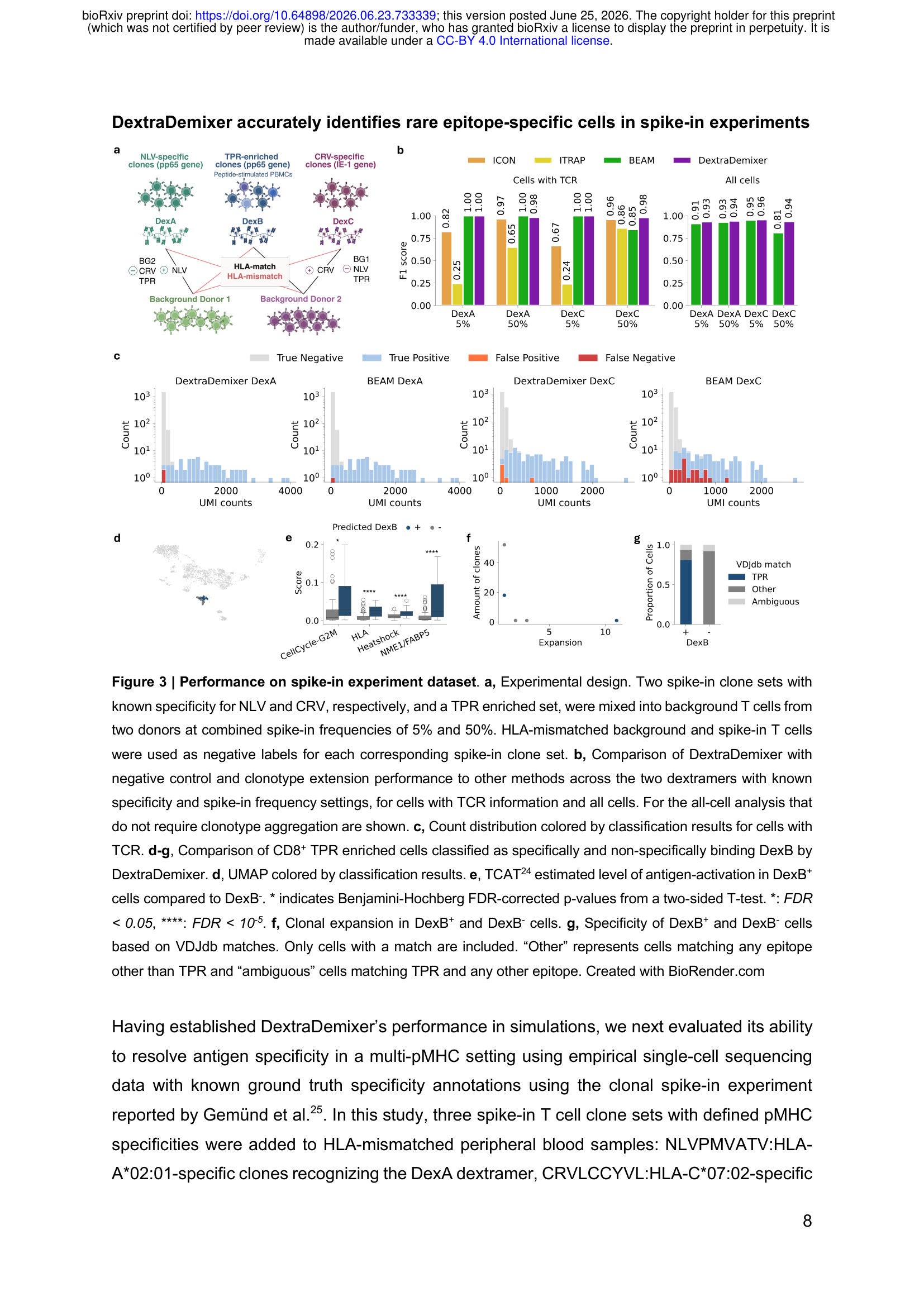
合成数据的表现无法代替真实实验,作者使用了Gemünd等人报告的克隆spike-in数据集作为有已知真值标签的外部验证:三组TCR克隆(NLV:HLA-A\*02:01, CRV:HLA-C\*07:02, TPR:HLA-B\*07:02),以5%或50%的频率混入背景PBMC,用BD Rhapsody平台完成10,000个T细胞的单细胞免疫组库测序。
DextraDemixer的完整模型(含负对照+克隆型)在四个子集上实现了平均F1 0.99(BEAM 0.96,ICON 0.86,ITRAP最低),且在其他方法表现明显下滑的DexC 50%设置(信号与背景重叠最严重)中F1达到0.98,而BEAM在这一设置的F1仅为0.85。
更值得注意的是DexC 5%的结果:该设置中只有3个真阳性细胞。DextraDemixer全部识别,0个漏检,0个假阳性。在稀有抗原特异性细胞的检测上,这个结果说明贝叶斯框架在极低频场景下确实有优势。
对于TPR富集细胞亚群(混合了特异性和非特异性细胞的DexB),DextraDemixer鉴定的DexB+细胞中有81%与VDJdb中已知TPR反应性TCR匹配,而DexB-细胞中0%匹配,同时DexB+细胞显示出更高的TCR依赖性激活基因程序(TCAT评分)和更强的克隆扩增。这表明分类结果具有生物学意义,而不只是统计上的区分。
SARS-CoV-2疫苗队列的应用
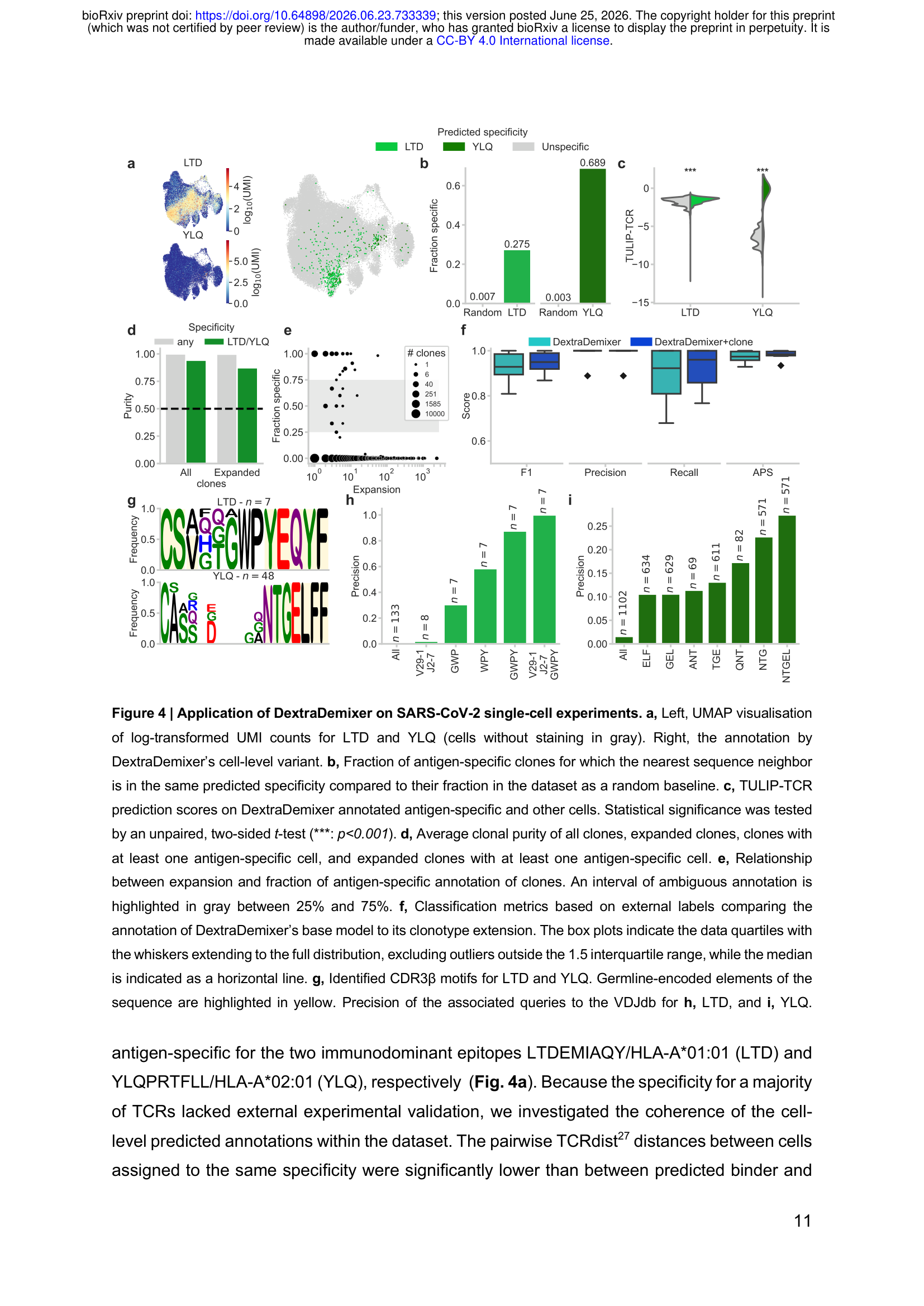
最后,作者将DextraDemixer应用于Kocher等人发表的纵向SARS-CoV-2疫苗数据集(53,907个细胞,来自两个免疫优势表位LTD:HLA-A\*01:01和YLQ:HLA-A\*02:01)。
在没有大量外部验证标签的情况下,作者通过内部一致性指标评估注释质量:
- TCR序列相似性:被注释为同一特异性的TCR之间,最近序列邻居是同一特异性的比例远超随机期望(LTD 27.5% vs 随机0.7%;YLQ 68.9% vs 随机0.3%)
- TULIP-TCR评分:DextraDemixer鉴定的抗原特异性细胞具有显著更高的计算预测结合评分(YLQ效果尤为明显,AUC 0.95)
- 克隆纯度:在扩增克隆中,99.9%的克隆内所有细胞获得相同注释;含有至少一个特异性细胞的克隆,纯度达87.3%
在序列motif挖掘方面,DextraDemixer的注释支持从65个YLQ特异性CDR3β序列中提取出含NTGEL基序的共同模式,这一模式在VDJdb中精准率达27.4%,相比数据库背景频率有实质性富集。LTD的结果因计算预测模型局限性(AUC仅0.62)不能完全解读,但序列motif分析同样显示了类似的VJ基因利用偏向。
几个值得关注的技术细节
为什么用负二项分布而非泊松
UMI计数的方差通常超过均值(过离散),负二项分布通过独立的离散参数捕捉这种过离散。DextraDemixer进一步通过色散系数约束信号组的均值-方差关系为线性,防止信号组不合理地吸收噪声组的概率质量——这是混合模型中一个常见的技术缺陷,文章明确指出并针对性解决了它(通过固定信号组的逆色散参数偏置 ζ₁=5)。
变分推断 vs. MCMC的取舍
作者选择黑盒变分推断(BBVI)而非MCMC的理由是计算效率,但明确承认这是近似后验而非精确后验。他们在Discussion中也提到MCMC采样可以提供更精确的估计(通过高度并行化计算),这是方法潜在的改进方向,尤其在FDR控制的可信区间估计上。
FDR控制的动态阈值
DextraDemixer提供了自动化的FDR控制机制:基于后验概率设定动态阈值,而非固定0.5截断。在模拟验证中,在目标FDR为0.01、0.05、0.1时,实际FDR均被控制在目标值以内;进一步利用完整后验分布进行可信区间界定(+cred.)可以进一步压低实际FDR,同时维持相近的召回率。对于需要高精度注释用于下游TCR训练数据收集的场景,这个特性尤为有价值。
方法边界:DextraDemixer不能回答什么
文章Discussion中诚实列出了几个开放问题:
1. 序列相似性尚未入模:当前模型把每个克隆型作为独立实体处理,没有利用相似TCR之间的信息共享(TCRdist意义上的邻近关系)。这在B细胞分析中尤其是问题,因为体细胞超突变会产生大量序列相似但克隆型不同的细胞。
2. pMHC独立性假设:模型假设各pMHC通道相互独立,没有建模竞争结合或交叉反应。对于高度重叠的pMHC库,这可能低估复合特异性。
3. 结合 ≠ 功能响应:DextraDemixer测量的是pMHC结合信号,而TCR-pMHC物理结合不等于T细胞功能激活。亲和力、抗原密度、共刺激、T细胞分化状态均影响功能结果。后验概率应理解为”抗原特异性结合概率”而非”功能性T细胞概率”。
在单细胞TCR图谱研究的语境中
pMHC多聚体实验和单细胞测序的结合生产了越来越多的TCR-抗原配对数据,这些数据是训练TCR特异性预测模型(如netTCR、ERGO、TULIP-TCR等)的基础原料。然而如果注释本身的精确率不足,下游模型将系统性偏斜——这是当前领域广泛讨论的数据质量问题。DextraDemixer的FDR控制机制和贝叶斯不确定性量化直接针对这个痛点:它不仅给出分类结果,还给出每个细胞的置信度,允许用户按照不同的质控严格度选取子集。
从工具生态位看,DextraDemixer的使用场景明确:有单细胞pMHC多聚体测序数据(10x Chromium/BD Rhapsody等),同时有负对照通道和TCR序列,就应该认真评估它相对BEAM的增益。对于没有TCR信息的批量实验,或者用传统流式细胞术而非测序平台的实验,方法的适用范围需要另作评估。
论文代码已发布于 GitHub:https://github.com/SchubertLab/DextraDemixer