在蛋白质组学PTM检测中,谷氨酰胺(Q)与天冬酰胺(N)的脱酰胺化——质量增加 +0.984 Da——是最常见的修饰之一,也是被最频繁误判的。核心矛盾在于:这个 0.984 Da 的质量偏移,与未修饰肽的 ¹³C 第一同位素峰(+1.003 Da)几乎完美重叠,差值仅 0.019 Da。对一条典型 tryptic 肽段(~1500 Da, z=2),两者在 m/z 上的差异约 0.01 Th,合 12 ppm。对于 Q-Exactive 这个数字是个边界值;对于 Orbitrap Astral,硬件已足够区分,但软件和搜索流程的默认参数却往往把分析者推回噪音区。
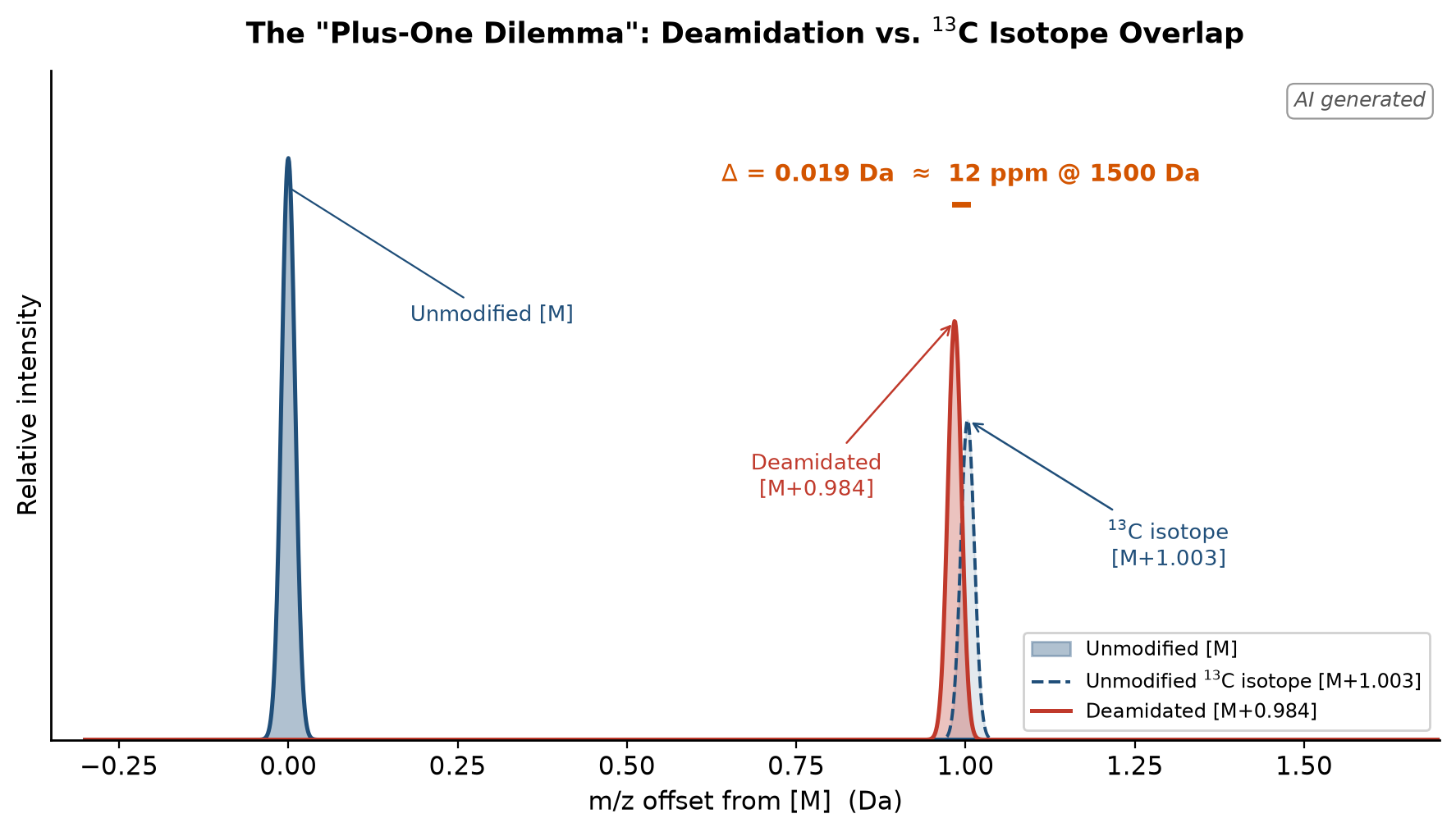
Figure 1. The mass-domain core of the problem: the deamidated peptide’s monoisotopic peak and the unmodified peptide’s 13C isotope peak are separated by only 0.019 Da (≈12 ppm @ 1500 Da).
Nepomuceno 等人 2014 年在 J Proteome Res 上的里程碑工作对此做了系统性解答。用 Q-Exactive 采集人血浆 DDA 数据,以 Mascot 在不同前体 tolerance 下重搜,得出至今被引的金规则:tolerance 收紧到 ≤5 ppm 时,脱酰胺化鉴定占比约 7.2%;放宽到 5–20 ppm,占比飙升至 95.7%,绝大多数是 ¹³C 同位素峰的误判。超过 5 ppm 红线,搜索引擎就开始把同位素峰当修饰来报。
Matrix Science 以一篇经典技术博文”The Plus One Dilemma”从搜库引擎侧面补充了关键判据:碎片证据是最终裁决者。真正的脱酰胺化会使含修饰位点的 b/y 离子系统性偏移 +1 Da,而同位素峰误判的所有碎片离子均为正常质量——因为它们实际上来自未修饰肽。文中给出了具体实例:同一条肽,Q14 脱酰胺化的 Mascot score 为 94(所有含 Q14 的 b/y 离子均含 +1 Da 偏移),同位素峰误判仅得 53,这个得分差在 FDR 1% 下完全可分。此外指出了 trypsin 特有的盲区:修饰位点靠近 N 端而谱图以 y 离子为主时,即使真修饰也可能缺乏足够的碎片证据。

Figure 2. MS2 fragmentation as the final arbiter. (A) True deamidation (Q→E, +0.984 Da): all b/y ions spanning or downstream of the modification site show a systematic +1 Da shift, scoring high in Mascot. (B) 13C isotope misassignment: no real modification exists, so all b/y ions retain normal mass and the score collapses.
从 Q-Exactive(MS1 140k @ m/z 200,外标 <5 ppm)到 Orbitrap Astral(MS1 480k @ m/z 200,外标 <3 ppm,内标 <1 ppm;MS2 80k,200 Hz),分辨率跃升了 3.4 倍。在 240,000 分辨率下,m/z≈800 处两峰相距 ~2.9× FWHM——已可分辨清晰的肩峰。但问题从来不只是硬件分辨率。真正的陷阱出现在 DIA 时代的搜索流程中。
Nepomuceno 论文基于 DDA+Mascot 流程——搜索引擎对每张 MS/MS 独立打分,碎片离子质量匹配是 scoring 核心。而今天 DIA-NN 和 Spectronaut 的鉴定机制有本质差异:DDA 中前体经 quadrupole 靶向隔离,MS2 碎片谱独立打分,修饰位点 b/y 离子 +1 Da 偏移是独立的加分项;DIA 中混合 MS2 靠库去卷积匹配,碎片信号容易被混合谱的模糊化所掩盖,+1 Da 的证据强度下降明显。同时,DIA-NN 自动推荐的前体 tolerance 常落在 7–10 ppm,刚好进入了 Nepomuceno 划定的高危区。一篇 2025 年的 DIA-NN FDR 评估显示其前体水平 FDR 约 0.54%,但针对脱酰胺化这一特定修饰的误判率并未单独评估。
更底层的困境在于:deamidated 肽的 monoisotopic peak 与未修饰肽的 ¹³C peak 在 m/z 上仅差约 0.01 Th(z=2),远小于 quadrupole 的隔离宽度,两者必然被共隔离、共碎裂。无论 DIA 窗口收得多窄,deamidation 与同位素峰的共碎裂都是物理上无法回避的——碎片谱里永远混着两种前体的信号。因此 MS1 层面的正交证据成了终极检验:DIA-NN 的 Ms1.Profile.Corr 一旦系统性偏低(中位数从 0.9 以上掉到 0.3 以下),那看到的基本就是同位素峰的影子。
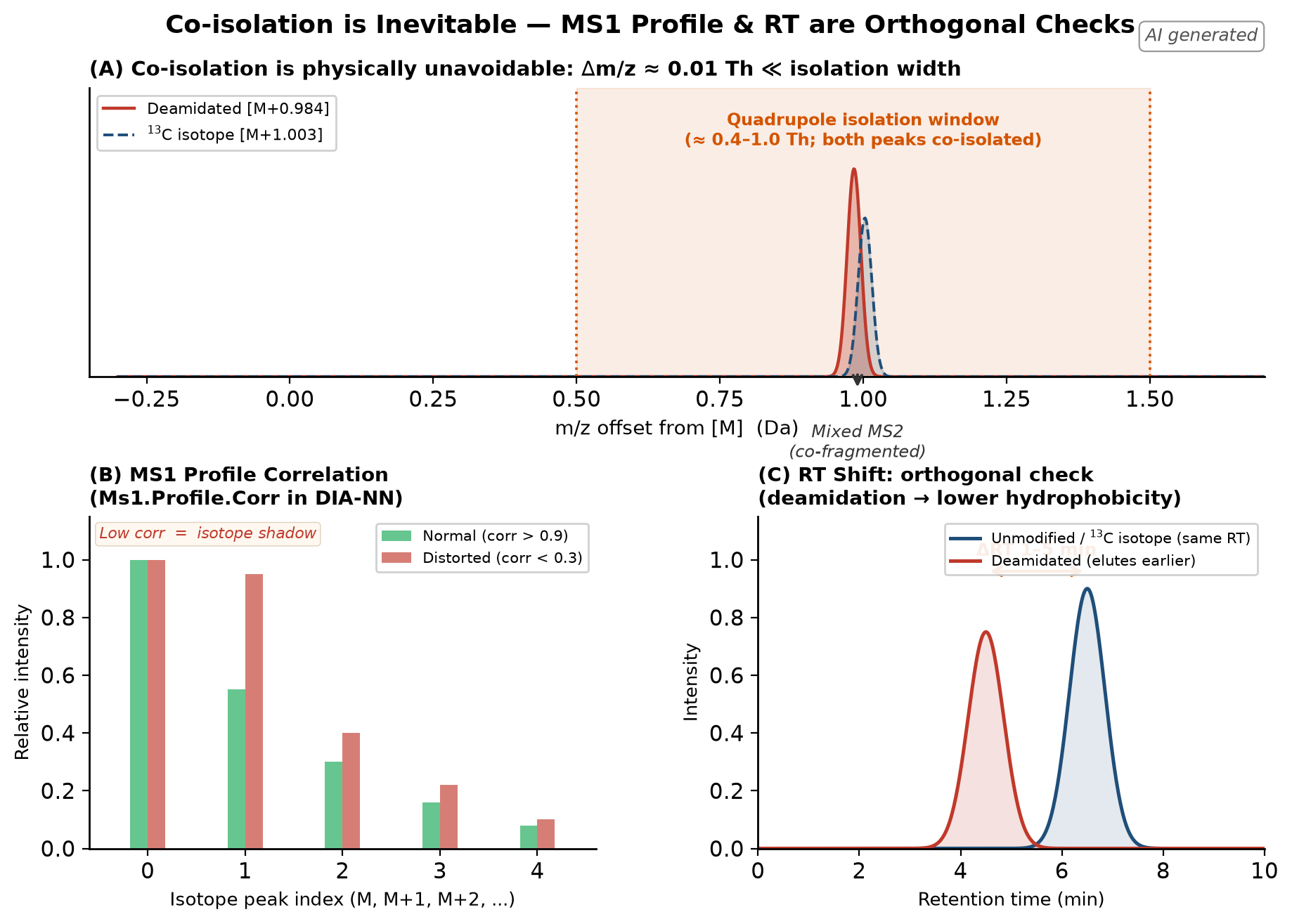
Figure 3. Co-isolation is physically unavoidable, and two orthogonal checks carry the burden. (A) Both the deamidated monoisotopic peak and the 13C isotope peak fall inside the quadrupole isolation window, producing a mixed MS2 spectrum. (B) The deamidated species can therefore only be validated at MS1 — through the isotope-envelope correlation (Ms1.Profile.Corr). (C) Retention-time shift provides a second, fully independent orthogonal line.
色谱维度提供了第二条正交线。脱酰胺化将酰胺基团(–CONH₂)转化为带负电荷的羧基(–COO⁻),显著降低了疏水性。在 C18 反相色谱中,脱酰胺化肽段比其未修饰版本提前约 1–5 分钟洗脱,方向固定、与 ¹³C 同位素峰(RT 完全相同)形成鲜明对比。但在各家软件的 scoring 中,这个 RT shift 是否被显式调用,实现差异很大。
综合上述文献与现实考量,笔者认为几条操作层面的判断值得注意:搜库 tolerance 收紧到 ≤5 ppm,Orbitrap Astral 条件下可考虑 2.5 ppm;强制检查 Ms1.Profile.Corr,中位数低于 0.3 是明确红灯;永远设对照组(WT vs 突变、未处理 vs 处理)来过滤化学伪影;对关键位点用 DDA 正交验证,因为 DDA 的碎片打分对此问题天然更友好。注意,如果一个”脱酰胺化”鉴定与未修饰版本在完全相同的 RT 窗口内共洗脱且基线完美重合,那几乎可以断定是同位素峰误判。
那么 Orbitrap Astral 为代表的 2026 年平台是否已经”解决”了这个问题?笔者的判断是:硬件分辨率和质量精度在物理上已足够——480k 分辨率下两峰相距 ~2.9× FWHM,足以形成可见肩峰——但 Nepomuceno 2014 划定的红线仍然是值得遵守的操作准则。问题的关键不在于仪器能不能区分,而在于 DIA 流程默认的搜库 tolerance 和 scoring 体系是否跟上了硬件换代。在同行普遍收紧默认参数之前,≤5 ppm 规则是最廉价也最有效的第一道防线。
内容经AI校正和润色,审慎阅读
参考文献: Nepomuceno AI, et al. Accurate Identification of Deamidated Peptides in Global Proteomics Using a Quadrupole Orbitrap Mass Spectrometer. J Proteome Res. 2014; 13(2): 777–785. | Matrix Science. The Plus One Dilemma. https://matrix-science.com/help/the_plus_one_dilemma.html | Orbitrap Astral Mass Spectrometer Specifications, Thermo Fisher Scientific, 2025–2026.